
Интеграция маркетингового подхода в общую систему менеджмента на предприятии требует, прежде всего, пересмотра основных принципов управления. Это во многом обусловлено необходимостью повышения гибкости внутренних бизнес-процессов и их координации с общей стратегией компании. Все более актуальной становится концепция управления отдельными бизнес-процессами, которая позволяет своевременно адаптироваться к изменениям внешней среды. Первоочередное внимание при этом уделяется повышению эффективности информационных коммуникаций между внутренней и внешней средой предприятия.
Система управления бизнес-процессами в качестве базового элемента должна рассматривать изменяющиеся потребности внешней среды, а в качестве главного информационного контура – систему управления маркетингом. Управление на основе информации предусматривает определение количественных пропорций и зависимостей между рыночными явлениями и факторами, которые на них влияют. На основании выводов и рекомендаций, полученных на этапе анализа, осуществляется стратегическое планирование маркетинга, уточняется структура комплекса маркетинга, а также выполняется оценка соответствия фактических и прогнозируемых показателей.
Исследованиям методологических аспектов оценки роли информации в процессе принятия решений посвящены работы многих зарубежных и отечественных ученых. Однако, несмотря на актуальность проблемы, в литературе практически не рассматриваются принципы управления предприятием на основе маркетинговой информации. В этой связи представляется важным исследование механизма преобразования информации, а также возможность ее практического использования для принятия управленческих решений.
Интеграция различных процессов в единое информационное пространство предприятия предполагает использование системного подхода к организации сбора, обработки и последующего анализа данных. Система маркетинговой информации (МИС) проектируется на основе комплексности и сбалансированности всех компонентов ее предметной области, что достигается за счет применения современных средств вычислительной и информационной техники. Первое определение МИС было дано в работе Cox D.F. и Good R.E. (1967 г.), в соответствии с которым МИС можно рассматривать как совокупность процедур и методов планового анализа и представления информации для принятия решений.
Дальнейшее исследование этого вопроса было связано с поиском универсального определения МИС исходя из общих задач, решаемых маркетинговой службой. Недостатком такого подхода является значительное упрощение информационных процессов. В связи с этим представляется важным определить основные функции МИС с учетом структуры цикла управления маркетингом на предприятии (Рис. 1).
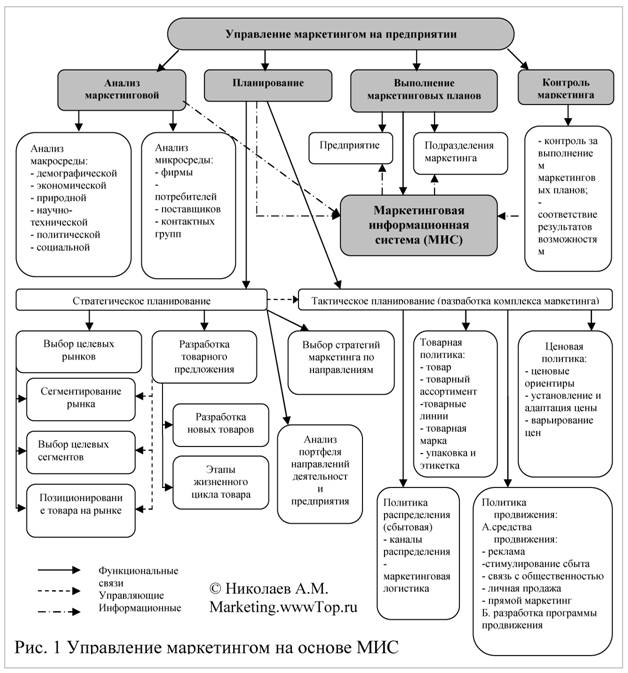
Таким образом, функции МИС в структуре предприятия могут быть представлены в виде маркетинговой системы поддержки принятия решений (MDSS – marketing decision support system), которая является начальным и конечным элементом информационных процессов.
Необходимо отметить, что структура и функциональные возможности МИС должны во многом зависеть от специфики и масштабов деятельности предприятия. Ф. Котлер выделяет четыре основных блока в структуре МИС [4,5]: подсистема внутренней отчетности, подсистема маркетингового наблюдения, подсистема маркетингового анализа и маркетинговых исследований.
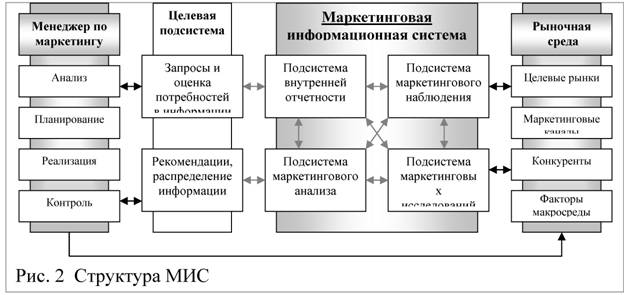
В отдельных работах достаточно подробно описывается классификация данных подсистем и основных источников информации [1,2,4]. При этом базовые методы преобразования и последовательного процесса передачи информации выносятся за рамки рассмотрения данного вопроса.
Для восполнения данного пробела взаимодействие между подсистемами необходимо представить в виде последовательного процесса сбора, хранения, обработки и анализа информации, необходимой для принятия управленческих решений. Эффективность и функциональность МИС будет во многом зависеть от степени автоматизации этих процессов [3]. Условно можно выделить два уровня (этапа) автоматизации системы. На первом уровне (характерном для малых и средних предприятий) отсутствует централизованная схема передачи информации. В этом случае информационное наполнение МИС производится из различных источников: подсистема внутренней отчетности – данные из CRM и (или) ERP систем (исполнители – отдел продаж и производство), а также из систем бухгалтерской отчетности, подсистема внешнего наблюдения и подсистема маркетинговых исследований – данные, собранные отделом маркетинга (исполнители – менеджеры по маркетингу). Хранение и анализ информации часто осуществляется с помощью офисных приложений (MS Access и MS Excel) либо прикладных программ. Преобразованная информация, как правило, используется на уровне высшего руководства для принятия стратегических решений. На втором уровне автоматизации (крупные компании и холдинги) происходит консолидация внутренней и внешней информации компании на основе корпоративных информационных систем (КИС) (маркетинг является одной из составляющих системы) либо унифицированных маркетинговых информационных систем. Эффективность маркетинговых служб достигается за счет регламентации процессов по обмену информацией с другими подразделениями.
В качестве основы модели МИС будем рассматривать базовые понятия автоматизации процессов, такие как базы данных, OLAP-анализ (on-line analytical processing), анализ информации с помощью статистических моделей и систем data-mining.
Реализация централизованного обмена информацией между подразделениями предприятия основана на возможности использования одних и тех же данных разными пользователями. Формирование собственных баз данных позволяет решать ряд конкретных прикладных задач, возникающих в ходе практической деятельности. Информация в базах данных структурируется в виде таблиц, которые представляют собой набор строк и столбцов, где строки соответствуют экземпляру объекта, конкретному событию или явлению, а столбцы – атрибутам (признакам, характеристикам, параметрам) этого объекта (Таблица 1).
Таблица 1
|
Дата |
Заказчик |
Товар |
Цена |
Кол. |
Сумма |
100 |
01.09.2008 |
Зак.1 |
Тов 1 |
10 |
20 |
200 |
101 |
01.09.2008 |
Зак.2 |
Тов 2 |
20 |
30 |
600 |
В приведенном примере столбцы «Дата», «Заказчик», «Товар» (группа товара, способ изготовления и др.) являются качественными параметрами, а столбцы «Цена», «Количество», «Сумма» (себестоимость, маржинальная прибыль, рентабельность и др.) содержат количественную оценку этих параметров.
Такие таблицы в том или ином виде являются наиболее распространенной формой хранения информации о продажах, клиентах (CRM-системы), поступлениях в производство и т.д. Для маркетингового анализа актуальной будет оценка качественных параметров в различных разрезах такой таблицы с помощью количественных параметров (заказчик «Зак.1» приобрел товар «Тов.1» общим количеством 20 ед. на общую сумму 200 ед.).
Необходимо отметить, что поля, содержащие качественные характеристики, могут содержать ряд перечисляемых значений и также могут быть представлены в виде таблицы. Например, поле «Заказчик» может быть представлено в следующем виде:
Таблица 2
|
Название |
Адрес |
Телефон |
Отрасль |
Тип |
1 |
Зак.1 |
Адрес 1 |
Телефон 1 |
Опт. торговля |
Конечный |
2 |
Зак.2 |
Адрес 2 |
Телефон 2 |
Машиностр. |
Посредник |
Как правило, такие таблицы содержат статические данные и часто называются справочниками. Связанные отношением таблицы взаимодействуют по принципу главная (master) – детальная (detail). В приведенном примере таблица продаж – главная (родительская), а таблица заказчиков – детальная (дочерняя).
Таким образом, главная таблица представляет собой многомерное хранилище данных, которое является основным источником для оценки количественных взаимосвязей между различными свойствами различных объектов.
На практике, часто используются двумерные срезы таких таблиц, которые выражают количественные отношения между двумя свойствами определенных объектов.
Таблица 3
Заказчик/Товар |
Тов.1 |
Тов.2 |
Тов.n |
Итого |
Зак.1 |
100 |
200 |
0 |
300 |
Зак.2 |
0 |
300 |
100 |
400 |
Зак.п |
200 |
0 |
100 |
300 |
Итого |
300 |
500 |
200 |
1000 |
В данном примере показан двумерный срез главной таблицы по свойству «Название заказчика» объекта «Заказчик» и свойству «Название товара» объекта «Товар». Также могут быть установлены количественные отношения между другими свойствами объекта «Заказчик» (отраслевая принадлежность, тип, регион и др.) и объекта «Товар» (группа товара, подгруппа, способ изготовления, упаковка и др.). Очевидно, что общее количество комбинаций свойств двух объектов будет равно m*n, где m – количество свойств первого поля, n – количество свойств второго поля. При этом следует учитывать, что в данном случае рассматриваются статические свойства, которые не меняются от заказа к заказу и заносятся в справочные (дочерние) таблицы. Например, товар «Тов.1» имеет определенный вид упаковки «Уп.1», который является постоянной характеристикой данного товара. Если свойство меняется от заказа к заказу, то оно должно быть представлено в виде отдельного поля в главной таблице, которому будет соответствовать своя справочная (дочерняя) таблица с перечислением видов упаковок (один и тот же товар «Тов.1» может иметь различные виды упаковок).
Таблица 4
|
Дата |
Заказчик |
Товар |
Упаковка |
Цена |
Кол. |
Сумма |
100 |
01.09.2008 |
Зак.1 |
Тов.1 |
Уп.1 |
10 |
20 |
200 |
101 |
01.09.2008 |
Зак.2 |
Тов.1 |
Уп.2 |
20 |
40 |
800 |
Технология представления многомерного хранилища данных в виде различных срезов часто обозначается термином OLAP (On-Line Analytical Processing). Технология OLAP позволяет снизить общую размерность многомерного хранилища данных (OLAP-куба) до необходимого уровня детализации. Необходимо отметить, что наиболее простыми инструментами реализации OLAP-технологии являются сводные таблицы в MS Excel (либо SQL-запросы в MS Access). Первый оцениваемый параметр заносится в область (поля) строк (таблица 3 – «Заказчик»), второй – в область столбцов («Товар»), количественные характеристики – в область данных (стоимость, прибыль и др.). Детализация полученных данных до необходимого уровня может осуществляться за счет использования нескольких параметров в области строк, столбцов или данных (в этом случае данные отражаются в виде вложенных таблиц) либо за счет использования области страниц (часто называются фильтрами). Для структурного анализа продаж в качестве фильтра используют временные показатели (год, месяц, неделю, день), что позволяет отразить данные многомерного хранилища за определенный промежуток времени. Поэтому наиболее демонстративным будет срез многомерного куба по трем осям – 1-ому и 2-ому параметру (свойствам объектов) и показателю времени.
Таблица 5
Дата |
01.09.2008 – Фильтр |
|||
Группа заказчика / Заказчик/ Товар |
|
Товар |
||
Группа Заказчика |
Заказчик |
Тов.1 |
Тов.2 |
Общий итог |
A |
Зак.1 |
200 |
|
200 |
|
Зак.2 |
|
300 |
300 |
A Итог |
|
200 |
300 |
500 |
| B | Зак.З |
|
500 |
500 |
|
Зак.4 |
|
400 |
400 |
B Итог |
|
|
900 |
900 |
Общий итог |
|
200 |
1200 |
1400 |
Если необходимо проследить динамику изменения свойств исследуемых объектов, то показатели времени заносятся в область строк.
Таблица 6
Заказчик/Товар/Время |
|
Время |
||||
Заказчик |
Товар |
Январь |
Февраль |
Апрель |
Март |
Общий итог |
Зак.1 |
Тов.1 |
100 |
800 |
|
|
900 |
|
Тов.2 |
300 |
|
1500 |
|
1800 |
Зак.1 Итог |
|
400 |
800 |
1500 |
|
2700 |
Зак.2 |
Тов.1 |
200 |
|
|
1200 |
1400 |
Зак.2 Итог |
|
200 |
|
|
1200 |
1400 |
Общий итог |
|
600 |
800 |
1500 |
1200 |
4100 |
В результате OLAP-анализа могут быть построены различные комбинации (ячейки многомерной таблицы), общее количество которых будет равно m1*m2*…*mn, где mi – количество значений i-го свойства. Общее количество
столбцов при таких комбинациях будет равно:
![]() ,
,
где m1*…*mn – произведение количества значений всех свойств, исключая i-е свойство.
Очевидно, что из всего множества необходимого выбрать только те наборы данных, которые будут иметь практическую значимость и использоваться для последующего статистического анализа (Рис. 3).

При этом важно определить последовательность и уровень детализации анализа. Например, при исследовании анализа динамики товарооборота фирмы по заказчикам (строка – «Название заказчика», столбец – «Время», количественная мера – сумма тыс. руб) было выявлено общее падение выручки за отчетный месяц (март) на 4 000 тыс. руб.
Таблица 7
Заказчик – Время |
Время |
|||
Заказчик |
Январь |
Февраль |
Март |
Общий итог |
Зак.1 |
262000 |
274000 |
275500 |
811500 |
Зак.2 |
155000 |
169000 |
172500 |
496500 |
Зак.п |
230000 |
246000 |
237000 |
713000 |
Общий итог |
647000 |
689000 |
685000 |
2021000 |
Одним из факторов снижения товарооборота в марте стало снижение дохода, полученного от заказчика «Зак.n» на 9000 тыс. руб. На следующем уровне детализации необходимо провести анализ дохода, полученного от заказчика «Зак.n» в разрезе реализованных ему товаров (строка – «Товар», столбец – «Время»). Очевидно, что снижение дохода могло произойти как за счет снижения количества отдельных товаров, приобретенных «Зак.n», так и за счет снижения цены на эти позиции. Поэтому для сравнительного анализа необходимо использовать две количественные характеристики – количество товара и сумму в денежных единицах.
Товар – Время; Фильтр Зак.n |
Время |
||||
Товар |
Данные |
Январь |
Февраль |
Март |
Общий итог |
Тов.1 |
Итог поле Сумма |
30000 |
32000 |
32000 |
94000 |
|
Итог поле Кол – во |
300 |
320 |
320 |
940 |
Тов.2 |
Итог поле Сумма |
120000 |
114000 |
114000 |
348000 |
|
Итог поле Кол – во |
400 |
380 |
380 |
1160 |
Тов.n |
Итог поле Сумма |
80000 |
100000 |
91000 |
271000 |
|
Итог поле Кол – во |
200 |
250 |
260 |
710 |
Итог по полю Сумма |
230000 |
246000 |
237000 |
713000 |
|
Итог по полю Кол. – во |
900 |
950 |
960 |
2810 |
|
Из таблицы видно, что снижение общего дохода от заказчика «Зак.n» в марте обусловлено снижением общей суммы, полученного от него за товар «Тов.n» на сумму 9000 тыс. руб., при одновременном увеличении количества этого товара на 10 ед. по сравнению с февралем. Из этого следует, что основным фактором уменьшения дохода стало снижение цены на товар «Тов.n». После анализа закупок остальных заказчиков, было обнаружено, что снижение цены на «Тов.n» привело к общему увеличению количества и общей суммы полученной за «Тов.n» от этих заказчиков в марте. На основании этого можно сделать вывод, что товар «Тов.n» обладает низкой эластичностью только для заказчика «Зак.n». Для уточнения этого показателя можно провести анализ относительных изменений цены и количества «Тов.n» по этому заказчику за более длительный интервал. Полученные выводы должны стать основой для принятия управленческих решений относительно метода ценообразования по товару «Тов.n» либо о необходимости использования дополнительных средств стимулирования сбыта в отношении заказчика «Зак.n».
Такая последовательность не является универсальной и может уточняться в зависимости от различных факторов деятельности компании. Если ассортимент включает небольшое количество наименований, то целесообразно начинать анализ продаж с изучения динамики товарооборота по отдельным позициям («Товар» – «Время»), только после этого изучать структуру продаж по заказчикам компании («Заказчик» – «Время», фильтр – «Товар»).
Статистические модели позволяют определенным образом преобразовать полученные наборы данных в прогнозные значения ключевых показателей, на основании которых осуществляется оптимальное планирование и принятие управленческих решений. Как правило, такое преобразование производится посредством группировки исходных данных, определения взаимосвязи между группами и определения прогнозных значений одних показателей с помощью других. Важно отметить, что необходимым условием для группировки должна быть преемственность исходных данных либо по оцениваемому свойству, либо по количественным характеристикам, либо по временным показателям.
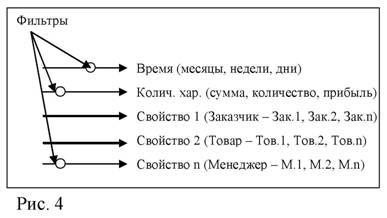
Заказчик – Товар |
Тов.1 |
Тов.2 |
Тов.n |
Зак.1 |
100 |
0 |
200 |
Зак.2 |
300 |
150 |
100 |
Зак.п |
0 |
50 |
60 |
Фильтры (месяц – январь, колич. хар. – сумма руб., менеджер – М.2)
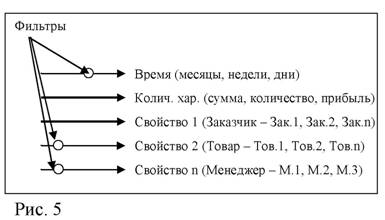
Заказчик Кол хар. |
Сум. |
Кол. |
Марж. Приб. |
Зак.1 |
200 |
5 |
150 |
Зак.2 |
400 |
15 |
320 |
Зак.п |
100 |
8 |
140 |
Фильтры (месяц – январь, товар. – Тов.n, менеджер – М.2)
На Рис. 4 и 5 показана группировка данных за определенный период времени, т.е. исследуется структура продаж (фильтр «Время» – обязательный). Анализ зависимости между группами часто затрудняется наличием большого числа факторов, изменяющихся при переходе от одного элемента группы к другому. Например, при оценке зависимости между группами «Тов.1» и «Тов.2» (столбцы таблицы Рис. 4), необходимо учитывать различия в характеристиках этих товаров, функциях, предпочтениях заказчиков и т.д. Для снижения влияния этих факторов и исследования однородных по своему содержанию групп можно использовать дополнительные фильтры («Группа товара», «Упаковка» и др.). Как правило, перед изучением зависимости между группами производится их оценка с помощью статистических показателей (средняя арифметическая, мода, медиана, среднее квадратическое отклонение, размах вариации, коэффициент вариации). Наиболее часто используется расчет средней арифметической взвешенной и дисперсии:
![]()
где xi – признак, mi – вес этого признака, n – количество элементов группы.
Например, средняя по группе «Тов.1» будет представлять собой среднюю сумму заказа товара «Тов.1», приобретенного одним заказчиком за выбранный период. Помимо расчета общей оценки группы, проводится классификация составляющих ее элементов. Критерием для классификации могут быть абсолютные или относительные показатели (наиболее часто используется показатель доли элемента в общей сумме), отсортированные по убыванию, либо интервальные значения группы, когда каждому элементу будет соответствовать определенный интервал совокупности. В маркетинговом анализе одним из основных инструментов классификации является анализ Парето (ABC – анализ). В общем случае закон Парето говорит о неравномерности распределения показателей – примерно 20% потребителей приносят 80% дохода. ABC-анализ позволяет выявить основные и малозначимые подгруппы элементов в соответствии с долей каждой подгруппы в общей сумме. Например, в группе «Сумма» (столбец «Сум.» Рис. 5) можно выделить три подгруппы заказчиков: подгруппа A – заказчики, которые обеспечивают 50% дохода (можно использовать другие значения – 60/30/10), подгруппа B и C – соответственно 40% и 10% дохода (количество подгрупп также может варьироваться: классический вариант – две подгруппы 80/20, либо несколько подгрупп ABCDE, если необходима более подробная классификация).
После общей оценки групп анализируется зависимость между ними. Одним из основных показателей зависимости между двумя случайными величинами является коэффициент парной корреляции.
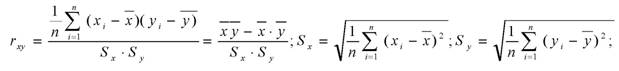
Значения r: от 0 до +/-0.3 – связь практически отсутствует, от +/-0.3 до +/-0.5 – слабая, от +/-0.5 до +/-0.7 – средняя, от +/-0.7 до +/-1 – сильная.
Например, если при оценке зависимости групп «Тов.1» и «Тов.2» (Рис. 4) будет выявлена положительная корреляционная связь, то можно предположить, что данные товары являются взаимодополняемыми для заказчиков компании (в случае отрицательной связи – взаимозаменяемыми, т.е. при увеличении спроса на товар «Тов.1», спрос на «Тов.2» будет падать). Для групп «Сумма» и «Количество» (Рис. 5) коэффициент корреляции не равен 1 (0,801), что свидетельствует о различии цен (скидок) на один и тот же товар для разных заказчиков (фильтр «Тов.n»).
После того, как выявлена взаимосвязь между двумя группами, необходимо дать математическое описание этой зависимости с помощью моделей регрессионного анализа, т.е. выбрать определенный вид функции, наилучшим образом отображающей характер изучаемой связи. Часто предполагается, что существует линейная зависимость между параметрами, которая описывается уравнением регрессии:
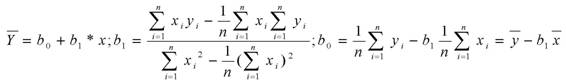
Анализ структуры данных за определенный интервал времени позволяет обнаружить неявные взаимосвязи между группами. В тоже время использование свойства объекта в качестве независимой переменной часто осложняется наличием большого числа субъективных факторов, которые могут изменяться при переходе от одного значения данного свойства к другому. Действие таких факторов поддается описанию, если в качестве аргументов для сравнения будут выступать не различные свойства объектов, а динамика одних и тех же свойств во времени. Таким образом, динамический ряд в отличие от случайной выборки имеет определенную последовательность и связан с переменной времени (Рис. 6, Рис. 7).
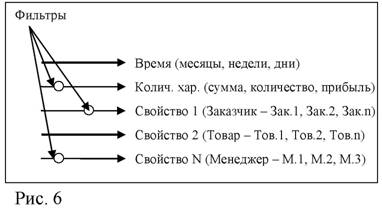
Время-Товар |
Тов.1 |
Тов.2 |
Тов.n |
Янв |
200 |
100 |
200 |
Фев |
400 |
250 |
100 |
Мар |
500 |
150 |
60 |
Фильтры (колич. хар. – сумма руб., заказчик – Зак.1, менеджер – М.2)
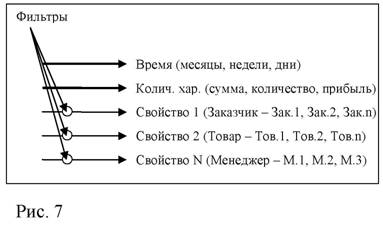
Заказчик Кол хар |
Сум. |
Кол. |
Марж. Приб. |
Янв |
200 |
5 |
150 |
Фев |
400 |
15 |
320 |
Мар |
100 |
8 |
140 |
Фильтры (заказчик – Зак.1, товар – Тов.n, менеджер – М.2)
На первом этапе анализа временных рядов также как и при анализе структуры данных за определенный интервал времени необходимо рассчитать обобщающие показатели каждой группы. Абсолютные и относительные показатели динамики могут рассчитываться по каждому элементу группы (для каждого значения времени – уровня ряда): базисные и цепные приросты уровней ряда, темпы роста и темпы прироста, либо для всей группы – средние величины данных показателей. В маркетинговом анализе одним из основных показателей динамики является частота (стабильность) и возможность прогнозирования будущих значений элементов группы. Для этого рассчитывается коэффициент вариации по каждому элементу группы, который характеризует степень отклонения параметра от его среднего значения.
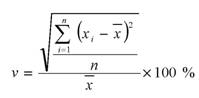
Результатом анализа является распределение элементов на три основные подгруппы: X – характеризуется стабильной количественной оценкой, Y – степень отклонения определяется с заданной точностью, Z – изменение оценки характеризуется нерегулярностью и низкой точностью прогнозирования (XYZ-анализ). На практике ABC и XYZ анализ проводятся параллельно с целью классификации элементов группы одновременно по величине количественной оценки элемента в общей структуре (принадлежность к одной из подгрупп А, B или C) и динамике изменения этого элемента во времени (принадлежность к одной из подгрупп X, Y или Z).
Существуют две основные цели анализа временных рядов: определение природы ряда и прогнозирование его будущих значений. При выборе методов прогнозирования, необходимо определить имеется ли зависимость исследуемого параметра от других переменных и есть ли прогнозные значения этих переменных. Если такой зависимости нет, то единственным показателем прогнозной модели будет фактор времени, при этом считается, что влияние других факторов несущественно или косвенно сказывается через фактор времени. В этом случае параметр х в приведенном выше уравнении регрессии заменяется на параметр времени t:
|
Выбор вида функции, описывающей тренд, параметры которой определяются методом наименьших квадратов, производится в большинстве случаев эмпирически, путем построения ряда функций и сравнения их между собой по величине среднеквадратической ошибки.
Таким образом, методы прогнозирования временных рядов во многом основаны на возможности экстраполяции детерминированной компоненты, которая может быть описана с помощью различных трендовых моделей, а также скорректирована с учетом систематических отклонений. Использование таких методов часто осложняется действием случайной компоненты, количественная оценка которой часто носит вероятностный характер. Поэтому для детерминации случайной компоненты используются казуальные (причинно-следственные) методы, в основе которых лежит изучение глубинных процессов и выявление скрытых факторов, определяющих поведение прогнозируемого показателя. К числу широко используемых казуальных методов относится корреляционно-регрессионный анализ, рассмотренный выше. В многомерном случае, когда используется более одной независимой переменной, уравнение регрессии имеет вид: Y = b0 + b1*x1+ b2*x2+ b3*x3+…+ bn*xn. В данном уравнении регрессионные коэффициенты (b-коэффициенты) представляют собой независимые вклады каждой переменной (xi) в предсказание зависимой переменной (Y). На практике часто исследуются зависимости между итоговыми значениями групп, без учета их внутренних взаимосвязей.
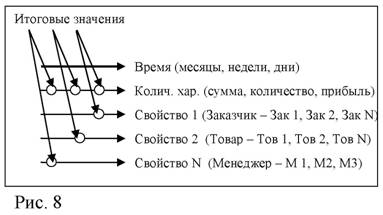
Время |
Зак.Сум. |
Тов.Кол. |
Мен.-Зар. |
Янв |
200 |
10 |
3 |
Фев |
400 |
15 |
7 |
Мар |
500 |
20 |
5 |
Итоговые значения (заказчик – сумма, товар – количество, менеджер – зарплата)
Например, в результате исследования динамики объема продаж (Рис. 8) было получено уравнение регрессии, которое с высокой степенью точности отражает фактические данные: Сумма (руб.) = -116,7 + 26,7*Товар (шт.)+ 16,7*Зарплата (руб.) (для расчета использовалась функция ЛИНЕЙН в MS Excel). Точность расчетных моделей определяется с помощью коэффициента детерминации и коэффициента Пирсона. В данном примере в качестве независимых переменных использовались апостериорные переменные, значения которых не могут быть известны заранее и используются только для описания зависимости между группами. Однако для прогнозирования показателей необходимы переменные, значения которых можно определить на входе анализа (априорно известные переменные – факторы продаж) для их дальнейшего преобразования с помощью выбранной модели и получения на выходе будущих значений функции (апостериорные значения – показатели продаж).
![]()
Выбор факторов предполагает их классификацию на факторы внешней среды и факторы внутренней среды организации. С точки зрения менеджмента все факторы можно разделить на управляемые и неуправляемые.
Таблица 9
Время – факторы продаж |
Управляемые |
Неуправляемые |
|||||
Количество посредников |
Количество менеджеров по продажам |
Средяя з.п. (% от продаж) |
Цена товара тыс. руб. |
Объем рекл. бюджета млн. руб. |
Уровень инфляции % |
Число аналог. товаров конкурентов |
|
|
x1t |
x2t |
x3t |
x4t |
x5t |
x6t |
x7t |
Январь |
5 |
6 |
2 |
11 |
0,1 |
100 |
4 |
Февраль |
4 |
6 |
3 |
14 |
0,15 |
108 |
6 |
Март |
4 |
5 |
2 |
12 |
0,11 |
118 |
3 |
С помощью методов регрессионно-корреляционного анализа оценивается зависимость объема продаж от каждого фактора (строится таблица попарных корреляций), а также определяются коэффициенты bi в уравнении регрессии. Если необходимо построить прогнозную модель прибыли, то к указанным факторам продаж добавляют факторы затрат.
Регрессионная модель является одной из самых распространенных моделей для математического описания зависимостей между различными группами переменных. В то же время многообразие и неоднородность маркетинговой информации часто обнаруживает необходимость использования сложных алгоритмов для выявления скрытых зависимостей. Многоаспектность данной проблемы сегодня рассматривается в рамках отдельного направления, часто обозначаемого термином Data Mining (интеллектуальный анализ данных). Data Mining представляет собой процесс выявления скрытых взаимосвязей внутри многомерных массивов информации. Как правило, выделяют пять стандартных типов закономерностей, которые являются объектом изучения Data Mining: ассоциация, последовательность, классификация, кластеризация и прогнозирование. На основе выявленных закономерностей формируются типовые шаблоны, которые интерпретируют исходные данные в информацию, необходимую для принятия управленческих решений.
Выводы. Использование маркетинговой информации становится необходимым условием повышения гибкости и эффективности системы управления предприятием. В тоже время внедрению МИС должен предшествовать этап описания внутренних бизнес-процессов предприятия и детализации основных количественных параметров для их оценки. Таким образом, проектирование МИС представляет собой сложный и многоэтапный процесс, в ходе которого уточняются методы алгоритмизации информационных процессов и способы их интерпретации для принятия управленческих решений.
Литература
- Баззел Р., Кокс Д., Браун Р. Информация и риск в маркетинге – М.:Финстатинформ 1993
- Беляевский И.К. Маркетинговые исследования: информация, анализ, прогноз. – М.: Финансы и статистика, 2001. – 578 с.
- Мхитарян С.В. Маркетинговая информационная система. – М.: Изд-во Эксмо, 2006. – 336 с.
- Голубков Е.П. Маркетинговые исследования: теория, методология и практика: Учебник. – 3-е изд., перераб. и доп. – М.: Издательство «Финпресс», 2003. – 496 с.
- Котлер Ф. Основы маркетинга. Краткий курс.: Издательство «Вильямс», 2007. – 656 с.